昨天成功地取得了vector agent搜集的metric和logger,在使用上因為metric算是一個附贈的功能,所以就不多著墨,可以依據這個概念自己去玩看看,有些人可能會有疑問在k8s上取得log的套件有很多,知名的如fluent-bit為什麼要選擇使用vector呢?
原因是他的支援相當的多,可以參考官方的說明https://vector.dev/#performance ,並且vector的角色可以自由地轉換,再來就是他的效能是較為優異的,附上數據圖
今天要講的是如何透過vector做基本的parser、transform以及收發。
如同昨天的架構中所示,整個logging的規劃中vector扮演的都是傳遞訊息的角色,讓無狀態的vector專注於傳輸,儲存放在kafka和接手的儲存服務,官方稱之為stream base topology vector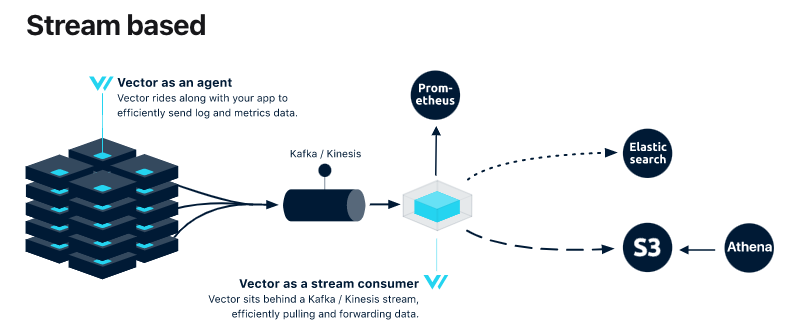
基於這個架構,最左邊的vector agent已經透過helm的方式完成了,接著就需要接收端的kafka與相對應的配置。
配置將log送到kafka官網有完整的default設置做法,就來試試看吧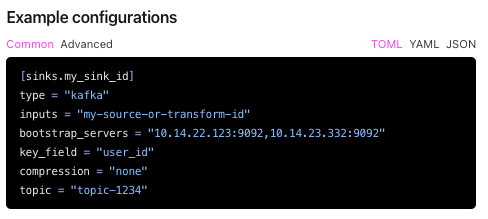
這是官網的簡介,其實官網還漏了一行encoding.codec = "json" ,運用這個寫法在inputs內寫入要丟過去的source並用”,”分隔,就可以丟到kafka囉,要如何區隔想要的log呢?
我使用了幾種方式解決不同需求
在kafka確認log有依據分類進來後,就可以開始準備統一管理所有cluster的vector了,因為是統一管理的為了跨cluster使用,我選擇用一台vm安裝vector,vector can run on anywhere的特性在此展現出來,首先取得rpm
wget https://packages.timber.io/vector/0.15.1/vector-0.15.1-1.x86_64.rpm
yum install vector-0.15.1-1.x86_64.rpm
安裝好之後可以在系統上看到
/etc/vector/vector.toml
/usr/lib/systemd/system/vector.service
/usr/bin/vector
vector.toml個是設定source和sink的檔案,vector.service是啟動服務用的service,vector是提供指令操作使用的;根據目前規劃的架構就在vector.toml調整source能夠取得kafka的topic並將sink調整為接下來要收log的loki即可,參考配置檔案如下
設定完成後,執行vector來運用[sinks.print]的機制看看是否有拉到kafka的topic,成功後就讓daemon啟動,之後log就都由這台主機管理也容易做後續的分類處理。

